
DATA PROCESSING
DATA AND DATA PROCESSING
Data are raw, unprocessed and unorganized (unstructured) facts and figures relating to business
activity. Data by itself has no meaning until when related data are brought together. Example is the
no of items sold, name of individual and many others.
Information is obtained by assembling data items into meaningful form for example the payroll, an
invoice, financial statement, or a report.
Data processing is the process of collecting and manipulating data items to produce meaningful
information.
DATA PROCESSING CYCLE
The data processing cycle is the order in which data is processed. There are four stages;
1 . Data collection
2. Data input
3. Data processing and storage
4. Data output
1 . DATA COLLECTION
There are several data-collection techniques that allow us to systematically collect data and
include the following:
Using available information
Usually there is a large amount of data that has already been collected by others, although it
may not necessarily have been analyzed or published. Locating these sources and retrieving
the information is a good starting point in any data collection effort
Observing
This is being part of the system where the person collecting data systematically selects,
watches and records specific situation or type of situations.
Interviewing (face-to-face)
An interview is a data-collection technique that involves oral questioning of respondents,
either individually or as a group.
Answers to the questions posed during an interview can be recorded by writing them down
(either during the interview itself or immediately after the interview) or by recording the
responses, or by a combination of both.
Administering written questionnaires
A written questionnaire (also referred to as self-administered questionnaire) is a data
collection tool in which written questions are presented that are to be answered by the
respondents in written form.
A written questionnaire can be administered in different ways, such as by:
Sending questionnaires by mail with clear instructions on how to answer the questions and
asking for mailed responses;
Gathering all or part of the respondents in one place at one time, giving oral or written
instructions, and letting the respondents fill out the questionnaires; or
Hand-delivering questionnaires to respondents and collecting them later.
The questions can be either open-ended or closed (with pre-categorised answers).
Focus group discussions
A focus group discussion allows a group of 8 – 1 2 informants to freely discuss a certain
subject with the guidance of a facilitator or reporter.
2. DATA INPUT
It is the process through which collected data is transformed into a form that the computer can
understand. It is a very important step because correct output result totally depends on the
input data. In this stage, the following activities are to be performed.
i) Verification
The collected data is verified to determine whether it is correct as required. If errors occur in
collected data, data is corrected or it is collected again.
ii) Coding
The verified data is coded or converted into machine readable form so that it can be
processed through computer.
iii) Storing
The data is stored on the secondary storage into a file. The stored data on the storage
media will be given to the program as input for processing.
3. DATA PROCESSING AND STORAGE
The main purpose of data processing is to get the required result. In this stage, the following
activities can be performed in a systematic manner. Some of the important activities are:
i) Classification
The data is classified into different groups and subgroups, so that each group or sub-group
of data can be handled separately.
ii) Storing
The data is arranged into an order so that it can be accessed very quickly as and when
required.
iii) Calculations
The arithmetic operations are performed on the numeric data to get the required results. For
example, total marks of each student are calculated.
iv) Summarising
The data is processed to represent it in a summarized form. Summary of data is often
prepared for top management. For example, the summary of the data of students is
prepared to show the percentage of pass and fail student examination etc.
4. DATA OUTPUT
Mostly, the output is stored on the storage media for later user. In output step, the following
1 42
activities can be performed.
i) Retrieval
Output stored on the storage media can be retrieved at any time and for different purposes.
ii) Conversion
The generated output can be converted into different forms. For example, it can be
represented into graphical form.
iii) Communication
The generated output is sent to different places. For example, weather forecast is prepared
and sent to different agencies and newspapers etc. where it is required.
DATA PROCESSING MODES
Interactive computing or Interactive processing:- refers to software which accepts input
from humans — for example, data or commands. Interactive software includes most popular
programs, such as word processors or spreadsheet applications. By comparison, noninteractive programs operate without human contact; examples of these include compilers
and batch processing applications. If the response is complex enough it is said that the
system is conducting social interaction and some systems try to achieve this through the
implementation of social interfaces.
Transaction Processing:- is information processing that is divided into individual, indivisible
operations, called transactions. Each transaction must succeed or fail as a complete unit; it
cannot remain in an intermediate state.
Batch Processing:- is execution of a series of programs (“jobs”) on a computer without
human interaction. Batch jobs are set up so they can be run to completion without human
interaction i.e. programs and data are collected together in a batch before processing starts.
This is in contrast to “online” or interactive programs which prompt the user for such input.
Spooling batch systems use the concept of spooling which is an acronym for simultaneous
peripheral operations on line. Spooling refers to putting jobs in a buffer, a special area in
memory or on a disk where a device can access them when it is ready.
Spooling is useful because device access data that different rates. The buffer provides a
waiting station where data can rest while the slower device catches up.
The most common spooling application is print spooling. In print spooling, documents are
loaded into a buffer and then the printer pulls them off the buffer at its own rate.
Real time processing
Data processing that appears to take place, or actually takes place, instantaneously upon
data entry or receipt of a command
Off-line and Interactive processing
Off-line is when the input/output devices are not in direct communication with the CPU.
Time sharing system
This involves accessing of one central computer by many users in which case the
processor time is divided into small units of time-slices, with each computer user being
allocated a time-slice
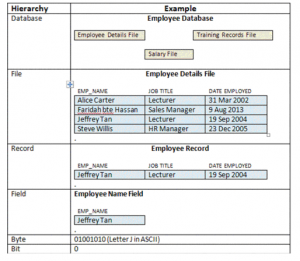
ELEMENTS OF DATA HIERARCHY
Data Hierarchy refers to the systematic organization of data, often in a hierarchical form. Data
organization involves databases, fields, records, files, bytes and bits.
Computers process all data items as combinations of zeros and ones
A bit is smallest data item on a computer, can have values 0 or 1
A byte is made of 8 bits
A character is a larger data item which can consists of decimal digits, letters and special
symbol
A data field holds a single fact or attribute of an entity. Consider a date field, e.g.
“September 1 9, 2004”. This can be treated as a single date field (e.g. birthdate), or 3 fields,
namely, month, day of month and year.
A record is a collection of related fields. An Employee record may contain a name field(s),
address fields, birthdate field and so on.
A file is a collection of related records. If there are 1 00 employees, then each employee
would have a record (e.g. called Employee Personal Details record) and the collection of 1 00
such records would constitute a file (in this case, called Employee Personal Details file).
Database – a group of related files
Files are integrated into a database. This is done using a Database Management System.
FILE ORGANIZATION AND ACCESS METHODS
There are a large number of ways records can be organised on disk or tape. The main methods of
file organisation used for files are:
Serial
Sequential
Indexed Sequential
Random (or Direct)
a) Serial Organization
Serial files are stored in chronological order, which is as each record is received it is stored in the
next available storage position. In general it is only used on a serial medium such as Magnetic tape.
This type of file organization means that the records are in no particular order and therefore to
retrieve a single record the whole file needs to be read from the begging to end. Serial organization
is usually the method used for creating Transaction files (unsorted), Work and Dump files.
b) Sequential Organization
Sequential files are serial files whose records are sorted and stored in an ascending or descending
order on a particular key field. The physical order of the records on the disk is not necessarily
sequential, as most manufacturers support an organization where certain records (inserted after
the file has been set up) are held in a logical sequence but are physically placed into an overflow
area. They are no longer physically contiguous with the preceding and following logical records, but
they can be retrieved in sequence.
c) Indexed Sequential Organization
Indexed Sequential file organization is logically the same as sequential organization, but an index is
built indicating the block containing the record with a given value for the Key field.
This method combines the advantages of a sequential file with the possibility of direct access
using the Primary Key (the primary Key is the field that is used to control the sequence of the
records). These days manufacturers providing Indexed Sequential Software allow for the building
of indexes using fields other than the primary Key. These additional fields on which indexes are
built are called Secondary Keys.
There are three major types of indexes used:
d) Random (or Direct)
A randomly organised file contains records arranged physically without regard to the sequence of
the primary key. Records are loaded to disk by establishing a direct relationship between the Key of
the record and its address on the file, normally by use of a formula (or algorithm) that converts the
primary Key to a physical disk address. This
relationship is also used for retrieval.
The use of a formula (or algorithm) is known as ‘Key Transformation’ and there are several
techniques that can be used:
Division Taking Quotient
Division Taking Remainder
Truncation
Folding
Squaring
Radix Conversion
These methods are often mixed to produce a unique address (or location) for each record (key)