MONDAY: 5 December 2022. Morning Paper. Time Allowed: 3 hours.
Answer ALL questions. This paper has two sections. SECTION I has twenty (20) short response questions of forty (40) marks. SECTION II has three practical questions of sixty (60) marks. Marks allocated to each question are shown at the end of the question.
SECTION I
1. What is the name given to big data that can be stored, accessed and processed in the form of fixed format? (2 marks)
2. What is the term given to heterogeneous sources characteristic and nature of big data? (2 marks)
3. Give an example of open source software framework used to develop data processing applications which are executed in a distributed computing environment. (2 marks)
4. Suggest a suitable name for a framework that clearly defines the components, layers to be used, and the flow of information in big data. (2 marks)
5. Give the meaning of temporal data mining. (2 marks)
6. ________________ is a file system that is used to scale a single Apache Hadoop cluster to hundreds of nodes. (2 marks)
7. When measuring data quality, name the factor that ensures that data is in the appropriate format. (2 marks)
8. PBC Ltd. has recently acquired a data warehouse that deals with large clusters of similar data items. Recommend the most suitable database management system for supporting this warehouse. (2 marks)
9. The examination of large amounts of data to see what patterns or other useful information can be found is known as
_________________________. (2 marks)
10. Name ONE common input format used in Hadoop file system. (2 marks)
11. Name ONE prominent Big Data visualisation tool. (2 marks)
12. In the 5 V’s of big data which one illustrates how a company can obtain data from many different sources like from
in-house devices to smartphone GPS technology? (2 marks)
13. _________________is a type of NoSQL database that uses tables with rows and columns to support big data design. (2 marks)
14. Write YARN in full as used in data management. (2 marks)
15. ____________________is a way of processing massive quantities of data that provides access to batch-processing
and stream-processing methods with a hybrid approach. (2 marks)
16. State one key big data infrastructure element. (2 marks)
17. List the command used to start up all the Hadoop daemons.
18. The MapReduce framework has seven important configuration parameters. Name ONE of these. (2 marks)
19. In a distributed database, concurrency control must be implemented. State ONE concurrency control technique. (2 marks)
20. Name a big data technology that focuses on the real-time processing of continuous flows of data in motion.
(2 marks)
SECTION II
21. Create a word processing document named “Question 21” and use it to save your answers to questions (a) to (c).
Explain the THREE main steps for deploying a Big Data solution. (6 marks)
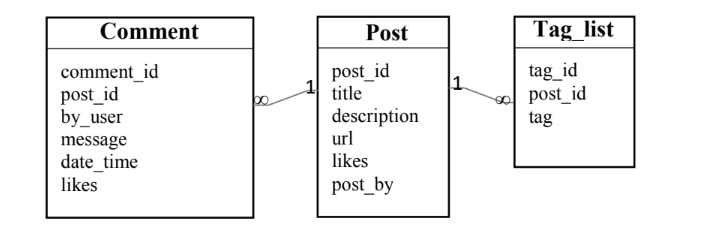
Study the following schema of a relational database and Convert it into a MongoDB schema. (6 marks)
3. An examiner graded students of Big Data Management as shown below. Create a stem and leaf plot and use it to explain the distribution of examination scores. (8 marks)
62, 64, 65, 65, 68, 70, 72, 72, 74, 75, 75, 75, 76,78, 78, 81, 83, 83, 84, 85, 87, 88, 92, 95, 98, 98, 100, 100.
Upload Question 21 Document.
(Total: 20 marks)
22. Create a word processing document named “Question 22” and use it to save your answers to questions (a) to (c).
Explain THREE core Reduce functions. (6 marks)
Consider a database with objects X and Y and assume that there are two transactions T1 and T2. T1 first reads X and Y and then writes X and Y. T2 reads and writes X then reads and writes Y. With adequate explanation, provide an example schedule that is NOT serialisable. (6 marks)
Explain why the use of a Hierarchical Data File Store (HDFS) in products like Hadoop can offer significant advantages when processing Big Data. (8 marks)
Upload Question 22 document.
(Total: 20 marks)
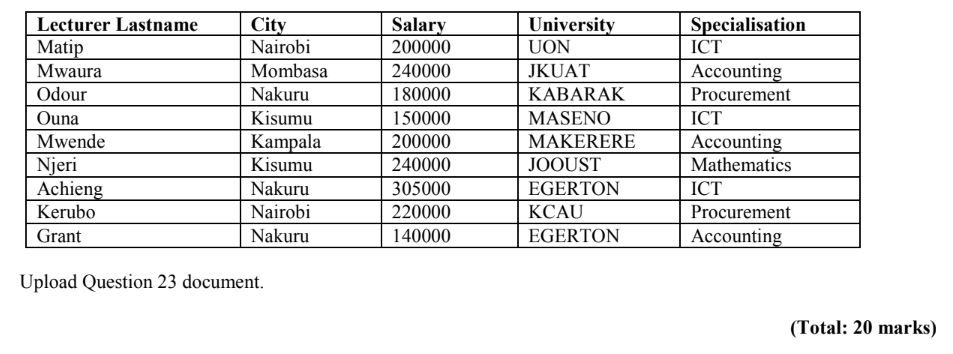
23. Create a word processing document named “Question 23” and use the word processor document to save your answers to questions 1 to 3.
Write the python MongoDB code to create a database called “BigData”. (5marks)
Write the python MongoDB code that will create a collection called “Lecturer” (5marks)
Write the python MongoDB code that will insert the data in the table below into the “Lecturer” collection.
(10 marks)