
Introduction
The objectives of this chapter are to:
- Explain the importance of data
- Describe the traditional file method of data storage
- Describe the database approach to data storage
- Compare and contrast the advantages and disadvantages of both the file and database methods of data storage
- Describe the principal types of databases
- Provide an overview of database design
- Explain how databases can improve business performance
- Discuss the management of data resources and data quality
THE IMPORTANCE OF DATA
Data is a vital organisational resource that needs to be carefully managed. The following are some of issues that impact on the management of organisational data:
- The amount of data being generated in information systems is growing at a phenomenal rate.
- Data must be stored for a long period of time, both for legal reasons and so it can be analysed to aid business decision making.
- Data is collected by many groups within in the organisation using different methods and technology.
- Data is stored using different servers, systems, databases and formats.
- Only a small fraction of an organisation’s data is appropriate for aiding any specific decision.
- An increasing amount of external data needs to be considered when making decisions.
- Data security, quality, and integrity are critical issues for those managing organisational data.
These issues highlight the need for careful planning and management of data within an organisation.
Most organisational data is associated with applications systems. The data may be inputted into the system or created during processing. Data is generally stored by the applications using one of two means:
- Files
- Databases
FILE ORGANISATION
The Traditional File Environment
Information cannot be used effectively if it is stored in a disorganised, inflexible manner. Without proper file management, it may be difficult or even impossible to extract information from an automated system. Retrieving a simple report can be timely and costly, if the information is not properly managed. File management must also be flexible enough to accommodate new pieces of information or to combine different pieces of information in changing ways. When computer files are poorly managed it will result in poor performance, high costs, and minimal flexibility.
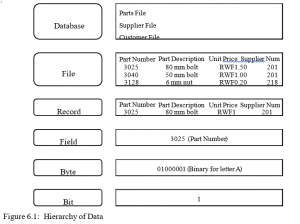
The Hierarchy of Data
The data hierarchy, as depicted in Figure 6.1, includes bits, bytes, fields, records, files, and databases. Data are organised in a hierarchy that starts with the bit, which is represented by either a 0 or 1. Bits can be grouped to form a byte to represent one character, number, or symbol. Bytes can be grouped to form a field, such as a name or date, and related fields can be grouped to form a record. Related records are combined to form files, and related files can be organised into a database.
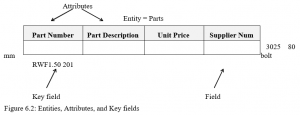
Entities, Attributes, and Key fields
An entity is a person, place, thing or event from which information can be obtained. An attribute is a piece of information describing a particular entity. A key field is a field in a record that uniquely identifies the record so that it can be retrieved, updated, or sorted (See Figure 6.2). For example, a product description may not be unique but a product number can be designed to be unique
Methods of File Organisation
There are three main methods of file organisation:
- Sequential file organisation: In this method of file organisation records are organised in order of the key field. If a particular record is required in a sequential file, all the prior records must be read before the required record is reached.
- Direct file organisation: Direct file processing or direct access allows the computer to go directly to the desired record by using a record key. To retrieve a record a formula is applied to the record key. The result is the disk address of the particular record. This operation is referred to as hashing. The record key is generated by the system. Direct access retrieves specific records quickly.
- Indexed file organisation: This method of file organisation is a form of compromise between the sequential and direct methods. The indexed file is made up of two files. The first file is a sequential file where the data is stored. The second file is an index file. It contains entries consisting of the key to each record and the address of that record. For a record to be accessed directly the key must be located in the index file and the address retrieved. The address is then used to retrieve the required record.
Problems associated with the File Environment
The use of a traditional approach to file processing encourages each functional area in a corporation to develop specialised applications and files. Each application requires its own unique data file.
The problems with the traditional file environment include data redundancy and confusion, program-data dependence, lack of flexibility, poor security, and lack of data sharing and availability.
Data redundancy is the presence of duplicate data in multiple data files. In this situation, confusion results because the data can have different meanings in different files.
Program-data dependence is the tight relationship between data stored in files and the specific programs required to update and maintain those files. This dependency is very inefficient, resulting in the need to make changes in many programs when a piece of data, has to be changed (e.g. changing the length of a data field).
Lack of flexibility refers to the fact that it is very difficult to create new reports from data when needed. Ad-hoc reports are impossible to generate and a new report may require programmers to modify the application so it can search the file for the particular information and output the report required.
Poor security results from the lack of control over the data because the data are so widespread.
Data sharing is virtually impossible because it is distributed in so many different files around the organisation and each file can only be accessed by its own application.
C. THE DATABASE APPROACH TO DATA MANAGEMENT
A database is an integrated collection of logically related data elements. A database consolidates records previously stored in separate files into a common pool of data elements that provides data for many applications. The data stored in a database is independent of the application programs using them and of the type of storage device on which they are kept. Therefore a single database can serve multiple applications. All the data is consolidated into a single database eliminating data duplication and redundancy. The data can therefore be shared by multiple applications.
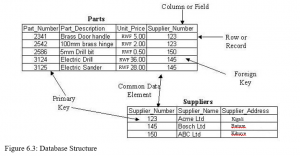
Database Structure
Database records are stored in tables with each table row representing a separate record. One field is designated the primary key and must hold a unique value for each record. A key field that identifies records in a different table is called a foreign key. Figure 6.3 shows an example of a simple database structure with two tables (Parts and Suppliers).
Database Software
A database is a store of data, while the software application that controls access to the database, is called the Database Management System (DBMS).
A Database Management System (DBMS)
The DBMS (see Figure 6.4) serves as an interface between the Physical database and the applications programs that use it. When an application calls for a data item, the DBMS locates it in the database and presents it to the application program. There is no need for the application to specify to the DBMS where the data is physically stored. The DBMS looks after the job of physically reading and writing of the data, which simplifies the job of the application program. However the application programs will still need to understand the logical structure of the data.
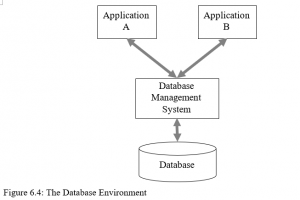
Figure 6.4: The Database Environment
A database management system (DBMS) is a collection of programs that enable users to create and maintain a database. The DBMS is a software system that facilitates the process of defining, constructing and manipulating databases
Defining a database involves specifying the data types, structures and constraints for the data to be stored in the database
Constructing the database is the process of storing the data itself on some storage medium that is controlled by the DBMS
Manipulating the database includes such functions as querying the database to retrieve specific data, updating the database to reflect changes to the data, and generating reports from the data.
The capabilities of the DBMS include the following:
- Controlling redundancy of persistent data
- Providing efficient ways to access a large amount of data
- Supporting a logical data model
- Supporting high-level languages to define the structure of data, access data and manipulate data
- Enabling concurrent access to data by multiple users
- Maintaining the integrity of the data
- Protecting the data from unauthorised access and malicious use
- Recovering from failures without losing data
- Being able to represent complex relationships among data
- Enforcing integrity constraints
- Providing persistent storage for program objects and data structures
Benefits of a DBMS
A database management system (DBMS) can:
- Reduce the complexity of the information systems environment
- Reduce data redundancy and inconsistency
- Eliminate data confusion
- Create program-data independence
- Reduce program development and maintenance costs
- Enhance flexibility
- Enable ad-hoc retrieval of information, improve access and availability of information Allow for the centralised management of data, their use, and security.
Database Management Systems (DBMS) Versus File Organisation Methods
Table 6.5 below summarises the advantages and disadvantages of both the database and file approaches.
Table 6.5: Comparing the Advantages and Disadvantages of DBMS and Flat File approaches
| DBMS Advantages over Flat file | FLAT FILE Advantages over DBMS |
| 1. Superior mechanism of retaining, controlling and managing tens, hundreds, thousands or millions of database records.
2. DBMS serve as an interface between application programs and a set of coordinated and integrated physical files called a database. 3. Data independence 4. Program independence 5. User not concerned with physical location of Data 6. View all data associated with a Unique search of Query 7. Generated Report options are excellent 8. Better revision control and maintenance of data and records (limited or no Data redundancy) 9. Back up of Data is centrally located |
1. Very cheap when compared to DBMS pricing
2. Does not require a Database Administrator (DBA) 3. Does not require expensive high performance computers (servers)
|
| DBMS Disadvantages over Flat file | FLAT FILE Disadvantages over DBMS |
| 1. Requires considerable resources
2. Initial cost of the Database 3. Generally requires a DBA 4. Staff Training Costs
|
1. Data Redundancy
2. Program / Data Dependency 3. Lack Of Flexibility 4. Poor Security 5. Lack Of Data sharing and availability 6. Lack Of Data integration |
Principal Types of Databases and Advantages and Disadvantages of Each
The principal types of databases include relational, hierarchical, network, and object-oriented.
Relational Database
The relational database model organises data into two-dimensional tables (see Figure 6.6). The relational model can relate any piece of information in one table to any piece of information in another table as long as the two tables share a common data element (such as a Supplier Number). Because relational DBMS can easily combine information from different sources, they are more flexible than the other DBMS structures. They can easily respond to ad-hoc inquiries. The main problem with relational DBMS is poor processing efficiency. Response time can be very slow if large numbers of accesses to data are required to select, join, and extract data from tables. Developments in relational technology, such as indexing, can overcome this problem.
Hierarchical Database
The hierarchical database model stores data logically in a vertical hierarchy resembling a tree-like structure. An upper record is connected logically to a lower record in a parent-child relationship. A parent segment can have more than one child, but a child can only have one parent. Hierarchical databases are good for treating one-to-many relationships. They can store large numbers of segments and process information efficiently, but they can only deliver information if a request follows the linkages of the hierarchy. Their disadvantages are their low user-friendliness, inflexibility and programming complexity. They are advantageous for high-volume, rapid response systems.
Network Database
The network model stores data logically in a structure that permits many-to-many relationships. Through extensive use of pointers, a child segment can have more than one parent. Network databases reduce redundancy and, like hierarchical databases, they process information efficiently. However, they are inflexible and are very complex to maintain and program.
Object-oriented Database
The object-oriented database stores data and the procedures acting on the data as objects that can be automatically retrieved and shared. Object-oriented databases can store complex types of information, but are slower at processing larger numbers of transactions when compared to relational DBMS.
Database Terms
Data Dictionary
A data dictionary is a collection of descriptions of the data items. The data dictionary defines the format needed to enter data into the database. The data dictionary contains information about each attribute in the database, such as its name, whether it’s a primary key or not and the type of data it is (numeric, alphanumeric, data, currency etc). For certain attributes a possible predefined set of values may be listed. A data dictionary would also contain information about who used the attribute (e.g. form, reports, applications etc).
Most database management systems keep the data dictionary hidden from users to prevent them from accidentally damage to its contents.
Structured Query Language (SQL)
Structured Query Language (SQL) pronounced either see-kwell or as separate letters SQL, is a standardised query language for requesting information from a database. Structured Query Language allows users to query a database and set up Ad-Hoc Reports.
The three most important SQL commands are SELECT, FROM, and WHERE.
- SELECT lists the columns from tables that the user wishes to see in a result table.
- FROM identifies the tables or views from which the columns will be selected.
- WHERE includes conditions for selecting specific records within a single table and conditions for joining multiple tables.
Example:
SELECT Part_Number, Part_Description, Unit_Price
FROM Parts
WHERE Unit_Price > RWF10
Data Redundancy
Data stored in separate files, as opposed to in a database, tends to repeat some of the same data over and over. Data redundancy occurs when different areas and groups within an organisation independently collect the same piece of information. Because it is collected and maintained in so many different places, the same data item may have different meanings in different. Different parts of the organisation and different names may be used for the same item. Also, the fields into which the data is gathered may have different field names, different attributes, or different constraints.
End User Involvement in selection and of a database management system
End users should be involved in the selection of a database management system and the database design. Developing a database environment requires much more than just selecting the technology. It requires a change in the company’s attitude toward information. The organisation must develop a data administration function and a data planning approach. The end-user involvement can be important in reducing resistance to sharing information that has been previously controlled by one organisational group.
The Role of the Database Administrator (DBA) The role of the Database Administrator (DBA) is to:
- Maintain a data dictionary. The data dictionary defines the meaning of each data item stored in the database and describes interrelations between data items.
- Determine and maintain the physical structure of the database.
- Provide the updating and changing the database, including the deletion of inactive records.
- Create and maintain edit controls regarding changes and additions to the database.
- Develop retrieval methods to meet the user’s needs.
- Implement security & disaster recovery procedures.
- Control configuration of the database and ensure that changes requested by one user must be first approved by the other users of the database before they are implemented.
- Assign user access rights in order to prevent unauthorised use of data.
- A DBA will work closely with users to create, maintain, and prevent damage to the database.
Database Design
To create a database environment, you must understand the relationship among the data, the type of data that will be stored in the database and how the data will be used. Database design must also consider how the organisation will use the data in the future, including sharing data with its business partners.
The creation of a new database involves two design stages; a logical design and a physical design stage. The logical design of a database is a model of the database from a business perspective, whereas the physical design shows how the database is arranged in the storage devices. The logical design requires a detailed description of the business information needs of the end users of the database.
The logical database design describes how the data elements in the database are to be grouped. The design process identifies relationships among data elements and the most efficient way of grouping data elements. Groups of data are organised and refined until an overall logical view of the relationships among all data elements in the database emerge.
To use a relational database, complex groupings of data must be simplified. The process of creating small, flexible data structures from complex groups of data is called normalisation. This process is illustrated in Figure 6.7 and 6.8. The advantage of normalisation is that it reduces redundancy and improves efficiency. In the example of the unnormalised relation (Figure 6.7) the supplier details would have to be recorded for each part they supply, while in the normalised tables (Figure 6.8) each suppliers details is only recorded once in the supplier table and is linked to each part using the “Supplier Num” field in the Parts table.
PARTS
| Part
Number |
Part Description | Unit Price | Supplier
Num |
Supplier
Name |
Address |
Figure 6.7: An unnormalised relation for PARTS
PARTS SUPPLIER
| Part
Number |
Part Description | Unit Price | Supplier
Num |
Supplier
Num |
Supplier
Name |
Address |
Figure 6.8: Normalised tables created from PARTS
ENTITY RELATIONSHIP DIAGRAMS
Database designers document their data model using an Entity Relational Diagram as shown in Figure 6.9. The diagram shows the relationship between the entities Salesperson, Customer, Orders, and Invoices. The boxes represent entities. The lines connecting the boxes represent relationships. A line connecting two entities that ends with a crow’s foot topped by a short mark indicates a one-to-many relationship. A line connecting two entities that end with no crow’s foot designates a one-to-one relationship. Figure 6.9 shows that one Salesperson can serve many Customers. Each Customer can place many orders but each order can only be placed by one customer. Each order generates only on Invoice.
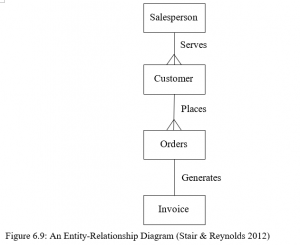
Figure 6.9: An Entity-Relationship Diagram (Stair & Reynolds 2012)
Distributing Databases
A distributed database is one that is stored in more than one physical location. A distributed database can be partitioned or replicated (duplicated). A partitioned database is divided into partitions so that there is local access to the data that it needs to serve its local area. These databases can be updated locally and later synchronised with the central database.
With replication, the database is duplicated at various remote locations. The central database can be partitioned so that each remote processor has the necessary data to serve its local area. Changes in local files are synchronised with the central. The central database can be replicated at all remote locations. Any change made to the database at one location is automatically replicated at all the other locations.
USING DATABASES TO IMPROVE BUSINESS PERFORMANCE
& DECISION MAKING
Businesses use their databases to:
- Keep track of basic transactions
- Provide information that will help the company run the business more efficiently
- Help managers and employees make better decisions
In companies with large databases and multiple systems, special technologies are needed to access data from the multiple systems and for analysing vast quantities of data. These technologies include data warehousing, data mining, and tools for accessing databases through the web.
Data Warehousing
A data warehouse is a centralised data repository (storage for data), which can be queried for business benefit. A data warehouse is a database that stores current and historical data that is of interest to the organisation. This data originates in many different information systems and from external sources, each with different data models. The data from the diverse applications are copied into the warehouse database as often as needed (hourly, daily, weekly etc). The data are transformed into a common data model and consolidated so that they can be used across the enterprise for management analysis and decision-making. The data are available for anyone to access as needed. Data warehouses are specifically designed to allow the warehouse users to:
- Extract archived operational data
- Overcome inconsistencies between different legacy data formats
- Integrate data from throughout an enterprise, regardless of location or format
- Incorporate additional information
The data warehouse concept is shown in Figure 6.10. The data warehouse is designed to provide the information to aid essential business decisions. The firm may need to change its business processes to benefit from the information in the warehouse.
Companies can build enterprise-wide warehouses where a central data warehouse serves the entire organisation. The company can also create smaller warehouses which focus on a single area of the company or individual information system, which are called data marts.
A data mart is a subset of a data warehouse in which a summarised or highly focused portion of the organisation’s data is placed in a separate database where it can be accessed by a specific group of users. A data mart will typically focus on a single subject area or line of business, so it usually can be constructed quicker and at lower cost than an enterprise wide data warehouse.
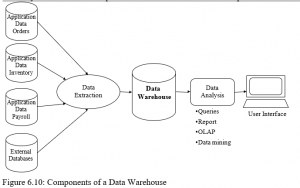
Figure 6.10: Components of a Data Warehouse
Business Intelligence, Data Analysis and Data Mining
Business intelligence refers to a series of analytical tools which works with data stored in databases to find patterns and insights for helping managers and employees make better decisions and improve organisational performance. Business intelligence provides organisation with the capability to collect and store information, develop knowledge about operations, and change decision-making behaviour, so as to achieve business objectives. Technologies such as data mining can be used to obtain knowledge and insight from analysing large quantities of data which is stored in databases. Business intelligence is discussed in more detail in Chapter 8.
Data Analysis
Data warehouses support multidimensional data analysis, also known as online analytical processing (OLAP). OLAP represents relationships among data as a multidimensional structure, which can be visualised as cubes of data, enabling more sophisticated data analysis.
Data Mining
Data mining is the analysis of data for hidden relationships. For example, the sales data for a particular brand of beer, is analysed and related to other market data, and may show a seasonal correlation with the purchase of other types of alcohol by the same individuals.
Data mining results include:
- Associations: when one occurrence can be correlated to another occurrence.
- Sequences: or one event leads to another event.
- Recognition of patterns and the creation of new organisation of data – for example analysing purchases to create customer profiles.
- Forecasting future trends as a result of finding patterns in the data.
Text Mining and Web Mining
Text mining and Web mining differ from conventional data mining in that the data is unstructured and comes from a variety of sources, where as conventional data mining focuses on structured data in databases and files.
TEXT MINING
Text mining focused on finding patterns and trends in unstructured data in text files. The data may be in email, memos, survey responses, legal cases, service reports etc. Text mining tools extract key elements from large unstructured data sets, discover patterns and relationships, and summarise the information.
WEB MINING
WEB mining can be used by businesses to understand customer behaviour, evaluate the effectiveness of a particular Web site, and measure the success of a marketing campaign. There are a number of different aspects to web mining:
- Web mining looks for patterns in data
- Web content mining extracts knowledge from the content of Web pages
- Web structure mining inspects data related to the structure of a particular site
- Web usage mining examines user interaction data recorded by a Web server whenever requests for a Web site’s resources are received.
Databases and the Web
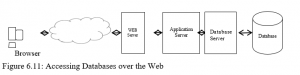
Databases play an important role in making organisations information resources available on the World Wide Web. A series of middleware and other software products have been developed to help users gain access to organisations’ legacy data through the Web. For example a customer with a Web browser might want to search an online retailer’s database for product information. Figure 6.11 shows how a customer might access the retailer’s internal database over the Web. The user would access the Web site over the Internet using Web browser on their PC. The Web browser requests data from the organisations database via the WEB server who in turn calls the application service who passes the request on to the Database Server. The following is a summary of the function of each server:
Database server
The database server runs the DBMS to process SQL statements and perform database management tasks.
Application server
This application system is installed on this server – this software handles all application operations. It also translates HTML commands into SQL so that they can be processed by the
DBMS.
Web server
This server presents WEB pages to users & passes user requests for data to the application server. The WEB server also delivers data in the form of web pages back to the user.
ADVANTAGES OF THIS APPROACH
This approach is a cost effective flexible approach. The WEB site can be setup without making changes to the internal database. Also, it costs much less to add a web interface in front of a legacy system than to redesign and rebuild the system to improve user access.
MANAGING DATA RESOURCES
Data planning may need to be performed to make sure that the organisation’s data model delivers information efficiently for its business processes and enhances organisational performance. There can sometimes be resistance in organisations to the sharing of information that has been previously controlled by one group. Creating a database environment is a long-term endeavour that requires significant investments and organisational change.
Information Policies
An information policy specifies the company’s rules for acquiring, classifying, standardising and sharing, information, and includes procedures and roles.
Data administration is responsible for the specific information policies and procedures through which data can be managed.
The Importance of Data Quality
Data residing in any database that is not accurate, timely, or does not contain relevant information will limit the effectiveness of an organisation. Organisations need to identify and correct faulty data and establish routines to edit and update data once a database becomes operational. Analysis of the quality of the data involves doing a data quality audit.
A data quality audit, involves a structured survey of the accuracy and level of completeness of the data in an information system. Data cleansing consists of activities for detecting and correcting data in a database that are incorrect or redundant. Data cleansing not only corrects data but also enforces consistency among different sets of data that originated in separate information systems.
Database design should include efforts to maximise data quality and eliminate error. Some data quality problems result from redundant and inconsistent data, but most stem from errors in data input. Organisations need to identify and correct faulty data and establish better controls for input and editing.
MANAGEMENT CHALLENGES AND SOLUTIONS
Developing a database environment requires much more than selecting database technology. It requires a formal information policy governing the maintenance, distribution, and use of information in the organisation. The organisation must also develop a data administration function and a data-planning. Data-planning is needed to make sure that the organisation’s data provides the information efficiently for its business processes and organisational decision making and contributes to enhanced performance. Resistance to the sharing of data must also be addressed.