
These are programs used to store & manage files or records containing related information. Refers to a collection of programs required to store & retrieve data from a database. A DBMS is a tool that allows one to create, maintain, update and store the data within a database.
DBMSs are system software that aid in organising, controlling and using the data needed by application programmes. A DBMS provides the facility to create and maintain a well-organised database. It also provides functions such as normalisation to reduce data redundancy, decrease access time and establish basic security measures over sensitive data.
DBMS can control user access at the following levels:
- User and the database
- Programme and the database
- Transaction and the database
- Programme and data field
- User and transaction
- User and data field
DBMS Architecture
Data elements required to define a database are called metadata. There are three types of metadata: conceptual schema metadata, external schema metadata and internal schema metadata. If any one of these elements is missing from the data definition maintained within the DBMS, the DBMS may not be adequate to meet users’ needs. A Data Definition Language (DDL) is a component used for creating the schema representation necessary for interpreting and responding to the users’ requests.
Data Dictionary and Directory Systems (DD/DS) have been developed to define and store in source and object forms all data definitions for external schemas, conceptual schemas, the internal schema and all associated mappings. The data dictionary contains an index and description of all the items stored in the database. The directory describes the location of the data and access method. Some of the benefits of using DD/DS include:
- Enhancing documentation
- Providing common validation criteria
- Facilitating programming by reducing the needs for data definition
- Standardising programming methods
FUNCTIONS OF A DATABASE MANAGEMENT SYSTEM
The DBMS is a set of software, which have several functions in relation to the database as listed below:
- Creates or constructs the database contents through the Data Manipulation Languages.
- Interfaces (links) the user to the database contents through Data Manipulation Languages.
- Ensures the growth of the database contents through addition of new fields & records onto the database.
- Maintains the contents of the database. This involves adding new records or files into the database, modifying the already existing records & deleting of the outdated records.
- It helps the user to sort through the records & compile lists based on any criteria he/she would like to establish.
- Manages the storage space for the data within the database & keeps track of all the data in the database.
ADVANTAGES OF DBMS:
- Data independence for application systems
- Ease of support and flexibility in meeting changing data requirements
- Transaction processing efficiency
- Reduction of data redundancy (similar data being held at more than one point – utilises more resources) – have one copy of the data and avail it to all users and applications
- Maximises data consistency – users have same view of data even after an update
- Minimises maintenance costs through data sharing
- Opportunity to enforce data/programming standards
- Opportunity to enforce data security
- Availability of stored data integrity checks
- Facilitates terminal users ad hoc access to data, especially designed query languages/ application generators.
IMPORTANCES OF DBMS
- A DBMS is complex software, which creates, expands & maintains the database, and it also provides the interface between the user and the data in the database.
- A DBMS enables the user to create lists of information in a computer, analyze them, add new information, and delete old information, and so on.
- It allows users to efficiently store information in an orderly manner for quick retrieval.
- A DBMS can also be used as a programming tool to write custom-made programs
PERFORMING DATA NORMALIZATION TO ENABLE DATA STORAGE IN A DATABASE
NORMALIZATION
Normalization is a method to remove all these anomalies and bring database to consistent state and free from any kinds of anomalies. If a database design is not perfect it may contain anomalies.
TYPES OF ANOMALIES
There are three types of anomalies;
1. Update anomalies
If data items are scattered and are not linked to each other properly, then there may be instances when we try to update one data item that has copies of it scattered at several places, few instances of it get updated properly while few are left with their old values. This leaves database in an inconsistent state.
2. Deletion anomalies
We tried to delete a record, but parts of it are left undeleted because of unawareness, the data is also saved somewhere else.
3. Insert anomalies
This happens when we trie to insert data in a record that does not exist at all.
Meaning of Terms
Key
An attribute or a set of attributes (columns) in a relation that uniquely identifies a tuple (row) in a relation.
Super Key
A super key is a set or one of more columns (attributes) to uniquely identify rows in a table. A super key is a combination of columns that uniquely identifies any row within a relational database management system (RDBMS) table.
Candidate Key
A candidate key is a closely related concept where the super key is reduced to the minimum number of columns required to uniquely identify each row. Candidate keys are selected from the set of super keys, and while selecting candidae key care should be taken so that it does not have any redundant attribute. For that reason they are also termed as minimal super key.Example
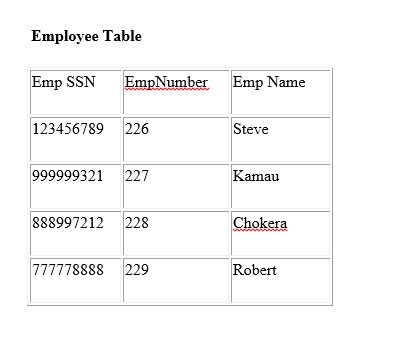
Super keys:
- {Emp_SSN}
- {Emp_Number}
- {Emp_SSN, Emp_Number}
- {Emp_SSN, Emp_Name}
- {Emp_SSN, Emp_Number, Emp_Name}
- {Emp_Number, Emp_Name}
All of the above sets are able to uniquely identify rows of the employee table.
Candidate Keys:
Are the minimal super keys with no redundant attributes.
- {Emp_SSN}
- {Emp_Number}
Only these two sets are candidate keys as all other sets are having redundant attributes that are not necessary for unique identification.
Super key vs Candidate Key
- All the candidate keys are super keys. This is because the candidate keys are chosen out of the super keys.
- When choosing candidate keys from the set of super keys only those keys from which we cannot remove any fields should be chosen. In the above example, we have not chosen {Emp_SSN, Emp_Name} as candidate key because {Emp_SSN} alone can identify a unique row in the table and Emp_Name is redundant.
Primary key:
Primary key is selected from the sets of candidate keys by database designer. So Either {Emp_SSN} or {Emp Number} can be the primary key
NORMALIZATION OF DATABASES
Database Normalisation is a technique of organizing the data in the database. Normalization is a systematic approach of decomposing tables to eliminate data redundancy and undesirable characteristics like Insertion, Update and Deletion Anamolies. It is a multi-step process that puts data into tabular form by removing duplicated data from the relation tables.
Normalization is used for mainly two purpose,
- Eliminating reduntant(useless) data.
- Ensuring data dependencies make sense i.e that data is logically stored.
TYPES OF ANOMALIES
Without Normalization, it becomes difficult to handle and update the database, without facing data loss. Insertion, Updating and Deletion Anomalies are very frequent if Database is not normalized. To understand these anomalies let us take an example of Student table.

Updating anomaly: To update address of a student who occurs twice or more than twice in a table, we will have to update S_Address column in all the rows, else data will become inconsistent. if data items are scattered and are not linked to each other properly, then there may be instances when we try to update one data item that has copies of it scattered at several places, few instances of it get updated properly while few are left with their old values. This leaves database in an inconsistent state.
Insertion anomaly: Suppose for a new admission, we have a Student Id(S_Id), name and address of a student but if student has not opted for any COURSE yet then we have to insert NULL there, leading to Insertion anomaly. We tried to insert data in a record that does not exist at all.
Deletion Anomaly: If (S_Id) 401 has only one COURSE and temporarily drops it, when we delete that row, entire student record will be deleted along with it. We tried to delete a record, but parts of it left undeleted because of unawareness, the data is also saved somewhere else.
Normalization Rules
Normalization rules are divided into following normal forms:
- First Normal Form
- Second Normal Form
- Third Normal Form
- BCNF
First Normal Form (1NF)
As per First Normal Form, no two Rows of data must contain repeating group of information i.e each set of column must have a unique value, such that multiple columns cannot be used to fetch the same row. Each table should be organized into rows, and each row should have a primary key that distinguishes it as unique.
The Primary key is usually a single column, but sometimes more than one column can be combined to create a single primary key. For example consider a table which is not in First normal form
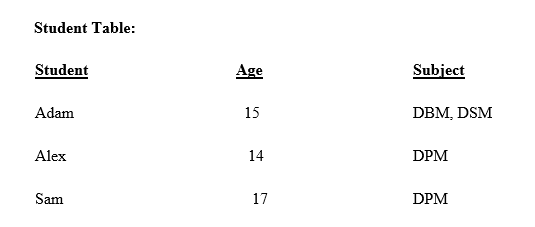
In First Normal Form, any row must not have a column in which more than one value is saved, like separated with commas. Rather than that, we must separate such data into multiple rows.
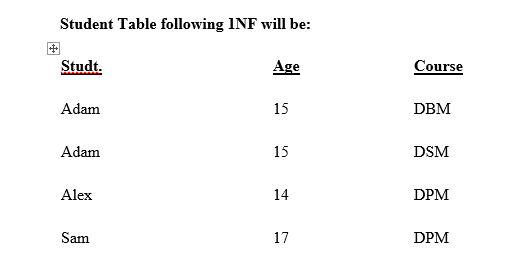
Using the First Normal Form, data redundancy increases, as there will be many columns with same data in multiple rows but each row as a whole will be unique. Each attribute must contain only single value from its pre-defined domain.
Second Normal Form (2NF)
As per the Second Normal Form there must not be any partial dependency of any column on primary key. It means that for a table that has concatenated primary key, each column in the table that is not part of the primary key must depend upon the entire concatenated key for its existence. If any column depends only on one part of the concatenated key, then the table fails Second normal form.
In example of First Normal Form there are two rows for Adam, to include multiple courses that he has opted for. While this is searchable, and follows First normal form, it is an inefficient use of space. Also in the above Table in First Normal Form, while the candidate key is {Student, Course}, Age of Student only depends on Student column, which is incorrect as per Second Normal Form. To achieve second normal form, it would be helpful to split out the courses into an independent table, and match them up using the student names as foreign keys.

In Student Table the candidate key will be Student column, because all other column i.e Age is dependent on it.
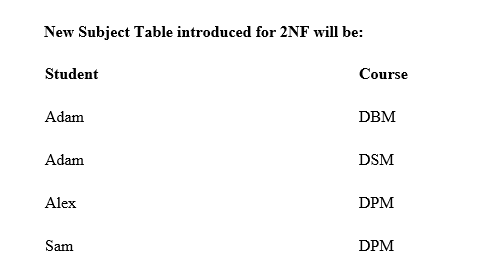
In Course Table the candidate key will be {Student, Subject} column. Now, both the above tables qualify for Second Normal Form and will never suffer from Update Anomalies. Although there are a few complex cases in which table in Second Normal Form suffers Update Anomalies, and to handle those scenarios Third Normal Form will be used.
NOTE
Prime attribute: an attribute, which is part of prime-key.
Non-prime attribute: an attribute, which is not a part of prime-key, is said to be a non-prime attribute. Second normal form says, that every non-prime attribute should be fully functionally dependent on prime key.
Third Normal Form (3NF)
Third Normal form applies that every non-prime attribute of table must be dependent on primary key, or we can say that, there should not be the case that a non-prime attribute is determined by another non-prime attribute. So, this transitive functional dependency should be removed from the table and also the table must be in Second Normal form. For example, consider a table with following fields.

The advantage of removing transitive dependency is,
- Amount of data duplication is reduced.
- Data integrity is achieved.
For a relation to be in Third Normal Form, it must be in Second Normal form and the following must satisfy:
- No non-primary attribute is transitively dependent on primary key attribute
- For any non-trivial functional dependency, X → A, then either
- X is a super key or,
- A is primary attribute.
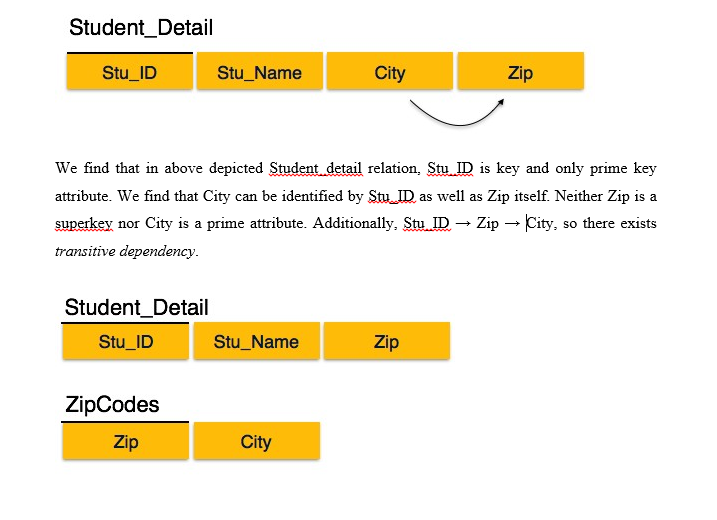
Boyce and Codd Normal Form (BCNF)
Boyce and Codd Normal Form is a higher version of the Third Normal form. This form deals with certain types of anomaly that is not handled by 3NF. A 3NF table which does not have multiple overlapping candidate keys is said to be in BCNF. BCNF is not commonly used.