

UNIVERSITY EXAMINATIONS: 2017/2018
EXAMINATION FOR THE DEGREE OF BACHELOR OF SCIENCE IN
INFORMATION TECHNOLOGY/ BACHELOR OF BUSINESS IN
INFORMATION TECHNOLOGY
BIT 3201A: DATA WAREHOUSING AND DATA MINING
BBIT 300: DATA MINING AND MANAGEMENT
FULL TIME/PART TIME/DISTANCE LEARNING
DATE: AUGUST, 2018 TIME: 2 HOURS
INSTRUCTIONS: Answer Question One & ANY OTHER TWO questions.
QUESTION ONE: 30 MARKS (COMPULSORY)
a) Explain the concept of a centroid in k-means clustering techniques (2 Marks)
b) Differentiate between classification and clustering. (4 Marks)
c) Discuss (shortly) whether or not each of the following activities is a data mining task.
(12 Marks)
i. Dividing the customers of a company according to their profitability
ii. Predicting the outcomes of tossing a (fair) pair of dice
iii. Predicting the future stock price of a company using historical records.
iv. Monitoring the heart rate of a patient for abnormalities
v. Extracting the frequencies of a sound wave.
vi. Monitoring and predicting failures in a hydropower plant.
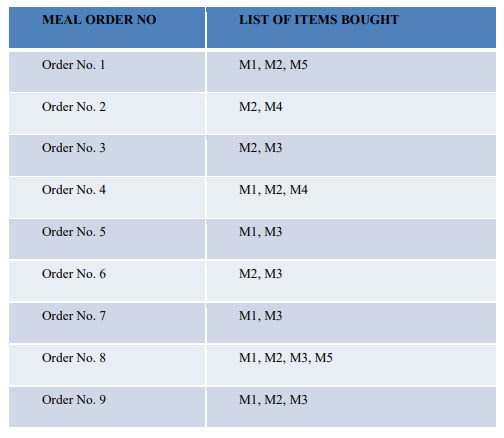
c) You are given the transaction data shown in the Table below from a fast food restaurant.
There are 9 distinct transactions (Order No. 1 – Order No. 9) and each transaction involves
between 2 and 4 meal items. There are a total of 5 meal items that are involved in the
transactions. For simplicity we assign the meal items short names (M1 – M5) rather than the
full descriptive names (e.g., Githeri, Chapati). Required: using Apriori Algorithm find the
association rules with support defined at 22% and the confidence is 78%. Show all your
working and justify your decisions where necessary. (12 Marks)
QUESTION TWO: 20 MARKS
a) Define the term Business Intelligence (2 Marks)
b) Using a well labeled diagram describe the Data-Information Hierarchy explaining its
importance to Organization decision making. (5 Marks)
c) Discuss five characteristics of good information that is needed by managers for decision
making. (5 Marks)
d) Discuss the basic difference between the agglomerative and divisive hierarchical clustering
algorithms and mention which type of hierarchical clustering algorithm is more commonly
used. (4 Marks)
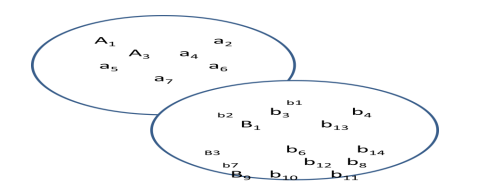
e) There are the two clusters A and B shown below? Explain what the problem is with such a
discovery from data mining (4 Marks)
QUESTION THREE: 20 MARKS
a) Describe “regression” data mining task (2 Marks)
b) Discuss any five desired features of cluster analysis algorithm. ` (5 Marks)
c) Discuss five ways in which the data that has been mined can be visually presented.
(5 Marks)
c) Giving examples, discuss four reasons why data cleaning stage in the KDD process is
necessary (4 Marks)
d) Discuss four causes of noisy data or erroneous data in the database (4 Marks)
QUESTION FOUR: 20 MARKS
a) Discuss five characteristics of OLAP (5 Marks)
b) Discuss any four factors that led to the growth and popularity of data mining.
(4 Marks)
c) Describe the various classification of data mining systems (6 Marks)
d) Discuss any five factors that you would consider when selecting and acquiring a data mining
software. (5 Marks)
QUESTION FIVE: 20 MARKS
a) Using two items A and B, define the following terms. (4 Marks)
i. Support
ii. Confidence
b) In the context of association rules mining Describe the following terms (4 Marks)
i. Frequent item-sets
ii. Confident rules
c) In building a decision tree, three possible attributes are considered as split attributes, the
information gain for the attributes A, B, and C are 0.97, 0.029, and 0.15 respectively. Which
attribute should be selected for the split and why? (3 Marks)
d) With the help of a diagram illustrate the Knowledge Discovery Process (9 Marks)