

UNIVERSITY EXAMINATIONS: 2018/2019
EXAMINATION FOR THE DEGREE OF BACHELOR OF SCIENCE IN
INFORMATION TECHNOLOGY /BACHELOR OF BUSINESS IN
INFORMATION TECHNOLOGY
BIT3201A BBIT300 DATA WAREHOUSING AND DATA MINING
FULL TIME/PART TIME/DISTANCE LEARNING
DATE: DECEMBER, 2018 TIME: 2 HOURS
INSTRUCTIONS: Answer Question One & ANY OTHER TWO questions.
QUESTION 1: 30 MARKS (COMPULSORY)
a) Discuss the basic difference between the agglomerative and divisive hierarchical clustering
algorithms and mention which type of hierarchical clustering algorithm is more commonly
used. 4 Marks
b) What is the difference between a data warehouse and a data mart? 2 Marks
c) Describe the steps and their purposes in knowledge discovery from databases,
8 Marks
d) Describe the “information gain” concept used in the decision tree algorithm. 4 Marks
e) Differentiate between classification and clustering. 4 Marks
f) Using two items A and B, define the following terms. 4 Marks
i. Support
ii. Confidence
g) In the context of association rules mining Describe the following terms 4 Marks
i. Frequent item-sets
ii. Confident rules
QUESTION 2: 20 MARKS
a) Using logarithm to base 2 tables calculate the information in tossing a die 4 Marks
b) Discuss five characteristics of OLAP 5 Marks
c) Describe the five major tasks that constitute data pre-processing 5 Marks
d) Describe the various classification of data mining systems 6 Marks
QUESTION 3:20 MARKS
a) Define the term clustering 2 Marks
b) Discuss any four desired features of cluster analysis algorithm. ` 4 Marks
c) Discuss four ways in which the data that has been mined can be visually presented.
4 Marks
d) A grocery shop sells six items which are Bread, Cheese, Eggs, Juice, Milk and Yogurt. The
shopkeeper also keeps a record of the transactions as follows.
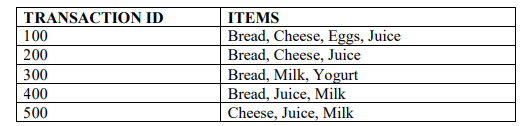
Using the improved naïve algorithm find the association rules with 50% and 75% confidence.
10 Marks
QUESTION FOUR: 20 MARKS
a) The table below shows the attributes of three students. Given that student 1 is the centroid of
the dataset, calculate the Manhattan distances of student 2 and student 3 from student 1.
10 Marks
Student Age Mark 1 Mark 2 Mark3

b) Data pre-processing and conditioning is one of the key factors that determine whether a data
mining project will be a success. For each of the following topics, describe in detail the
affect this issue can have on our data mining session and what techniques can we use to
counter this problem. 10 Marks
i. Noisy data
ii. Data type conversion
QUESTION 5: 20 MARKS
We’ve covered the following data mining techniques in this course. For each technique identified
below, describe the technique, identify which problems it is best suited for, identify which
problems it has difficulties with, and describe any issues or limitations of the technique.
20 Marks
i. Decision trees
ii. Association rules
iii. K-Means algorithm