

UNIVERSITY EXAMINATIONS: 2017/2018
EXAMINATION FOR THE DEGREE IN BACHELOR OF SCIENCE IN
INFORMATION TECHNOLOGY/
BACHELOR OF BUSINESS INFORMATION TECHNOLOGY
BIT 3201A/BBIT 300: DATA WAREHOUSING AND DATA MINING
MODE: FULL TIME/PART TIME/DISTANCE LEARNING
ORDINARY EXAMINATIONS
DATE: NOVEMBER, 2017 DURATION: 2 HOURS
INSTRUCTIONS: Answer question ONE and any other TWO questions
QUESTION ONE [30 MARKS]
a) Define a data warehouse.
[1 Mark]
b) Discuss THREE benefits of implementing a data warehouse.
[3 Marks]
c) Briefly explain the following concepts as used in data warehousing and data mining:
i. Knowledge
ii. Data driven decision making
iii. Data governance (DG).
iv. Data mining
v. Granularity
vi. Data visualization.
[6 Marks]
d) Describe the characteristics of the data held in a data warehouse.
[4 Marks]
e) Discuss how data marts differ from data warehouses and identify the main reasons for
implementing a data mart.
[8 Marks]
f) Describe OLAP applications and identify the characteristics of such applications.
[5 Marks]
g) Differentiate between MOLAP and ROLAP models as used in OLAP.
[3 Marks]
QUESTION TWO [20 MARKS]
a) Describe the generic steps in classification method in data mining
[4 Marks]
b) Clustering, in data mining, can be defined as a process of partitioning a set of data (or
objects) into a set of meaningful sub-classes, called clusters. In this regard, describe any
four requirements for clustering.
[4 Marks]
c) Given two objects represented by the tuples (22,1,42,10) and (20,0,36,8) calculate the
following distances between the two objects. Calculate the minkowski distance if p=3.
[4 Marks]
d) Discuss any FOUR issues used to measure the performance of a data mining system.
[8 Marks]
QUESTION THREE [20 MARKS]
a) Describe the following possible integration schemes for data mining system and data
warehouse
i. Loose coupling
ii. No coupling
iii. Tight coupling
[6 Marks]
b) Explain the difference between Association rule mining and frequent
itemset mining
[2 Marks]
c) Given are the following five transactions on items {A, B, C, D, E}:
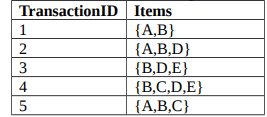
Use the Apriori algorithm to compute all frequent itemsets, and their support, with minimum
support 2. It is important that you clearly indicate the steps of the algorithm.
[6 Marks]
d) Briefly explain whether each of the following activities is a data mining task.
i. Dividing the customers of a company according to their profitability.
ii. Predicting the outcomes of tossing a (fair) pair of dice
iii. Monitoring the heart rate of a patient for abnormalities.
[6 Marks]
QUESTION FOUR [20 MARKS]
a) Differentiate between ordinal and nominal variable.
[2 Marks]
b) Discuss the architecture of a typical data mining system.
[6 Marks]
c) Describe any THREE data cleaning methods
[3 Marks]
d) Explain the difference between predictive and descriptive data mining
[2 Marks]
e) Explain why it is advisable to separate a data warehouse from operational database.
[3 Marks]
f) Explain any FOUR different data mining functionalities
[4 Marks]
QUESTION FIVE [20 MARKS]
a) Using a neat diagram discuss the various phases of knowledge discovery in databases.
[7 Marks]
b) Define support and confidence to measure the strength of association rule. Calculate the
support and confidence for the rules jam=> (butter, bread) and butter=>bread from the
following:
Basket 1: bread, butter, jam
Basket 2: bread, butter
Basket 3: bread, butter, milk
Basket 4: beer, bread.
[7 Marks]
c) Describe any THREE applications of data mining
[6 Marks]