
MONDAY: 1 August 2022. Morning paper. Time Allowed: 3 hours.
This paper has two sections. SECTION I has twenty (20) short response questions of forty (40) marks. SECTION II has three practical questions of sixty (60) marks. All questions are compulsory. Marks allocated to each question are shown at the end of the question.
SECTION I
1. The ______________precomputes results using a distributed processing system that can handle very large quantities of data. It aims at perfect accuracy by being able to process all available data when generating views. (2 marks)
2. The ___________includes one fact table which is connected to several dimension tables, which can be connected to other dimension tables through a many-to-one relationship. (2 marks)
3. A set of illegal instructions that are inserted into a legitimate computer program is known as _______________. (2 marks)
4. It is a column-oriented non-relational database management system that runs on top of Hadoop Distributed File System (HDFS). It provides a fault-tolerant way of storing sparse data sets, which are common in many big data use cases. It is well suited for real-time data processing or random read/write access to large volumes of data. This is the ________________
5. Which is the method where analytical data is loaded into memory for live calculations and querying? (2 marks)
6. An ________ is an observation that lies an abnormal distance from other values in a random sample from a population. (2 marks)
7. ___________ tracker plays the role of scheduling jobs and tracking all jobs assigned to the task tracker. (2 marks)
8. Identify the operator that is used to execute a shell command from the Hive shell. (2 marks)
9. Data _________ is the process of moving data from various sources into a central repository such as a data warehouse where it can be stored, accessed, analysed, and used by an organisation. (2 marks)
10. A __________________is a data visualization tool that is a graphical portrayal of data that uses different colors to address different values. This difference in color representation makes it easy for the viewers to understand the trend more quickly. (2 marks)
11. MongoDB does not require a relational database management system (RDBMS), so it provides an elastic data storage model that enables users to store and query multivariate data types with ease. The key-value pair that forms the basic unit of data in MongoDB is known as a _______________________. (2 marks)
12. The open-source software that facilitates the collecting, aggregating and moving of huge amounts of unstructured, streaming data such as log data and events in data big data analytics is called? (2 marks)
13. In graph data structure ______________ describes how a connection between a source node and a target node are related. (2 marks)
14. __________________is an open-source, distributed processing system used for big data workloads and utilises in- memory caching, and optimised query execution for fast analytic queries against data of any size. (2 marks)
15. ________________ is a file system that handles large data sets running on commodity hardware? It is used to scale a single Apache Hadoop cluster to hundreds of nodes. (2 marks)
16. In distributed computing the ability to support billions of job requests over massive datasets is referred to as ______. (2 marks)
17. _________ is a set of processes and activities across an organisation to support a data strategy and guide technology, people and data procedures. (2 marks)
18. This is the active and continuous management of data through its life cycle. It includes the organisation and integration of data from multiple sources and to ascertain that the data meets given quality requirements for its usage. It covers tasks related to controlled data creation, maintenance and management such as content creation, selection, validation or preservation. This activity in the big data value chain is referred to as___________. (2 marks)
19. _____________ architecture is a way of processing massive quantities of data that provides access to batch- processing and stream-processing methods with a hybrid approach (2 marks)
20. There are three type of big data; structured, semi-structured or unstructured. In which category does XML data belongs to? (2 marks)
SECTION II
21. Create a word processing document named “Question 21”. Use the word processor document to save your answers to questions 1 to 5 in form of screenshots.
1. Demonstrate how you would create the table below and save it as SALES DATA in the YEAR directory of drive C then load the data of the file into an external hive table using an appropriate command. (4 marks)
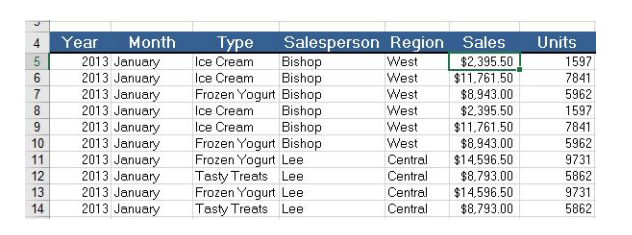
2. Explain how you could retrieve the data from the database using an appropriate command and display the output. (3 marks)
3. Type the Hive function that will display the Month and Region for all Sales that are greater than $11000. (5 marks)
4. Type the Hive function that will count the Units that are realised from sales by sales person called Lee. (4 marks)
5. Explain the Hive function that will display the year and type for all sales from the Central region then order by type in descending order (4 marks)
Upload question 21 document.
(Total: 20 marks)
22. Create a word processing document named “Question 22”. Use the word processor document to save your answers to questions 1 to 3 in form of screenshots.
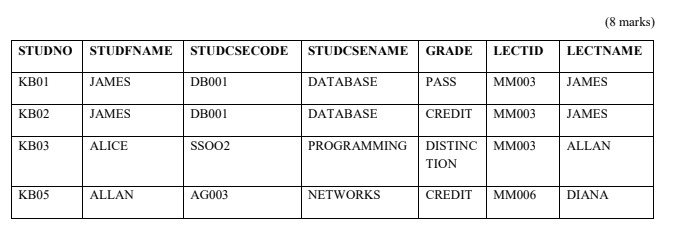
1. Give the commands showing how you will use a database to create and insert data into a table called Grade whose contents are as shown below.
2. State the Hadoop pig commands that can be used to perform the following
Pasting spark code lines in the shell. (2 marks)
Execute system commands and check return code. (3 marks)
Executing system commands and checking output. (3 marks)
3. Type the command for creating a database to store tables in Hadoop HIVE. (4 marks)
Upload question 22 document.
(Total: 20 marks)
23. Create a word processing document named “Question 23”. Use the word processor document to save your answers to questions 1 to 4 in form of screenshots.
1. Type the following dataset into excel worksheet. Create an HDFS folder in drive C: and name it BIG DATA.
Save the excel worksheet in BIG DATA folder as a comma separated version (CSV) file and name it Candidate.csv (5 marks)
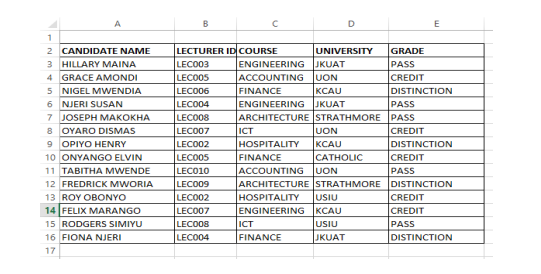
2. Explain how you would use a command to load the data into an external hive table with column labels and show the table contents. (6 marks)
3. Explain the procedure of moving the external table to an internal Hive table that uses the ORC format and show the table contents.(5 marks)
4. Stat the command for creating a partitioned table from the internal hive table on question 3 above. (4 marks)
Upload question 23 document.
(Total: 20 marks)