

UNIVERSITY EXAMINATIONS: 2018/2019
EXAMINATION FOR THE DEGREE OF BACHELOR OF SCIENCE IN
INFORMATION TECHNOLOGY /BACHELOR OF BUSINESS IN
INFORMATION TECHNOLOGY
BBIT300 BIT3201A DATA MINING AND DATA WAREHOUSING
FULL TIME/PART TIME/DISTANCE LEARNING
DATE: APRIL, 2019 TIME: 2 HOURS
INSTRUCTIONS: Answer Question One & ANY OTHER TWO questions.
QUESTION ONE
a) Briefly explain the term data mining.
[2 Mark]
b) With the aid of a suitable diagram, describe the main steps involved in knowledge discovery
process.
[6 Marks]
c) Using examples, describe the following data mining functionalities
i). Data characterization and discrimination
ii). Cluster analysis
iii).Outlier analysis
iv).Association
[8 Marks]
d) With the aid of a suitable example explain the term association rule
[2 Marks]
e) Discuss whether or not each of the following activities is a data mining task.
i). Dividing the customers of a company according to their gender.
ii). Sorting a student database based on student identification numbers.
iii).Predicting the outcomes of tossing a (fair) pair of dice.
iv).Predicting the future stock price of a company using historical records.
v). Monitoring seismic waves for earthquake activities.
[5 Marks]
f) The table below provides a classification for a data set of X Y pairs
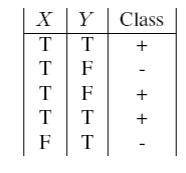
i). Calculate the entropy for this classification.
[2 Marks]
ii). Calculate the information gain for X and Y.
[5 Marks]
QUESTION TWO
a) Explain the term data warehouse.
[2 Marks]
b) Explain the following data warehouse models
i). Enterprise warehouse
ii). Data mart
[4 Marks]
c) Distinguish between top down and bottom up approaches to building a data warehouse.
[4 Marks]
d) Describe the steps followed in a data warehouse design.
[4 Marks]
e) Explain the term online Analytical Processing (OLAP)
[2 Marks]
f) Describe the following types of OLAP.
i). Relational OLAP (ROLAP)
ii). Multidimensional OLAP (MOLAP)
[4 Marks]
QUESTION THREE
a) Explain the following terms.
i). ItemSet
ii). Support
iii).Confidence
iv). conviction of a rule
[4 Marks]
b) Explain the Apriori algorithm used in data mining. [2 Marks]
c) Given the data below, use the Apriori algorithm to generate the L3 itemset. The minimum
support is 2 (two)

[6 Marks]
d) List the association rules that can be extracted from this data. The minimum confidence
(min_conf) is 50%
[4 Marks]
e) Describe the following approaches for mining multilevel association rules
i). Uniform Minimum Support
ii). Reduced Minimum Support
[4 Marks]
QUESTION FOUR
a) Briefly explain the significance of data pre-processing in a data mining process
[2 Marks]
b) Explain any three methods that can be used to fill in missing values for attributes during the
data pre-processing stage of knowledge discovery process
[6 Marks]
c) Describe the concept of dimension reduction as a technique of data reduction.
[4 Marks]
d) Study the following table and then answer the following questions
For each of the following tasks, describe briefly what, if anything, you would need to do to
the above dataset before using a decision tree learning algorithm.
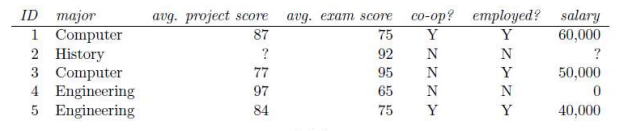
[8 Marks]
QUESTION FIVE
a) Machine learning (ML) deals particularly with the following two cases: supervised and
unsupervised. Characterize each of them and explicitly point their mutual differences.
[4 Marks]
b) Using examples, distinguish between classification and prediction forms of data analysis as
used in data mining
[4 Marks]
c) Describe the two phases of decision tree generation
[2 Marks]
d) A dataset collected in an electronics shop showing details of customers and whether or not
they responded to a special offer to buy a new laptop is shown in table above. This dataset
has been used to build a decision tree to predict which customers will respond to future
special offers.
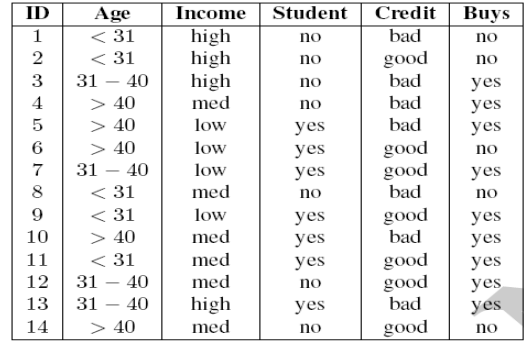
Use the ID3 algorithm to come up with a decision tree that models the above training
examples
[10 Marks]