
 UNIVERSITY EXAMINATIONS: 2011/2012
UNIVERSITY EXAMINATIONS: 2011/2012
THIRD YEAR EXAMINATION FOR THE BACHELOR OF
SCIENCE IN INFORMATION TECHNOLOGY
BIT 4204 DATA WAREHOUSING AND DATA MINING
EXAMINITION
DATE: AUGUST, 2012 TIME: 2 HOURS
INSTRUCTIONS: Answer Question ONE and any other TWO
QUESTION ONE
a) Differentiate between data mining for characterization and data mining for
discrimination (4 Marks)
b) Discuss any six desired features of cluster analysis. (6 Marks)
c) With the help of a diagram illustrate the Knowledge Discovery Process (8 Marks)
d) Describe any four types of data that are gathered and be mined and state the type of
organizations that gather these types data (4 Marks)
e) Using two items X and Y, define the following terms. (4 Marks)
i. Support
ii. Confidence
f) In the context of association rules mining Describe the following terms. (4 Marks)
i. Frequent itemsets
ii. Confident rules-
QUESTION TWO
a) Define the term pruning and explain its application in data mining. (4 Marks)
b) Discuss six ways in which the data that has been mined can be visually presented.
(6 Marks)
c) Discuss five benefits of data mining. (5 Marks)
d) Discuss any five challenges facing data mining. (5 Marks)
QUESTION THREE
a) Define the following terms (4 Marks)
i. Data warehousing
ii. Data mining
b) By use of appropriate examples discuss the following possible discoveries from a data
mining exercise. (4 Marks)
i. Classification
ii. Prediction
iii. Clustering
iv. Outlier Analysis
c) Discuss six factors that lead to the growth and popularity of data mining. (6 Marks)
d) Describe the various classification of data mining systems. (6 Marks)
QUESTION FOUR
a) Define an OLAP system (2 Marks)
b) Discuss five characteristics of OLAP (5 Marks)
c) Discuss three factors that influence the selection and acquisition of data mining
software. (3 Marks)
d) Consider a retail shop with the following set of transactions
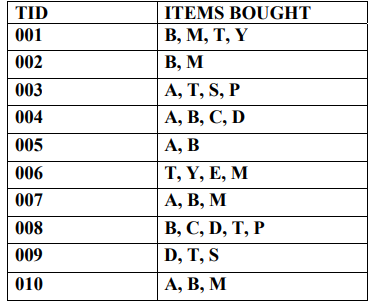
Using the improved Apriori algorithm find the association rules with 30% and 60%
confidence.
(10 Marks)
QUESTION FIVE
a) Describe four distance measures in cluster analysis (4 Marks)
i. Euclidean distance
ii. Manhattan distance
iii. Chebychev distance
iv. Categorical data distance
b) The table below shows the training data for classifying bank loan applications by
assigning applications to one of the risk classes.
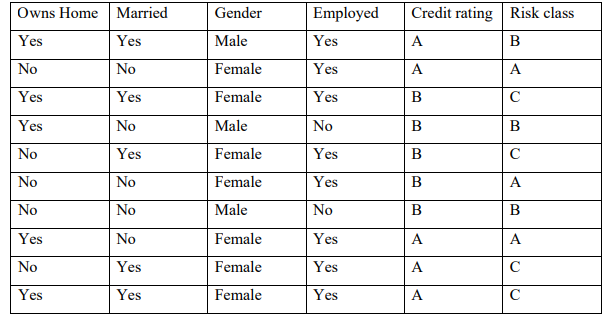
i. Using the split algorithm, find the attribute that has the highest information gain.
(12 Marks)
ii. Draw the decision tree for the table above (4 Marks)