
 UNIVERSITY EXAMINATIONS: 2013/2014
UNIVERSITY EXAMINATIONS: 2013/2014
ORDINARY EXAMINATION FOR THE BACHELOR OF SCIENCE
IN INFORMATION TECHNOLOGY
BIT 3201A DATA WAREHOUSING AND DATA MINING
DATE: AUGUST, 2014 TIME: 2 HOURS
INSTRUCTIONS: Answer Question ONE and any other TWO
QUESTION 1: 30 MARKS (COMPULSORY)
a) Define the following terms giving examples in each case (6 marks)
i) Data Normalization
ii) Data Binning
iii) Data cube
b) Differentiate between OLTP and OLAP indicating examples (6 marks)
c) Before data warehousing it is apparent that data preprocessing must be carried out.
Describe the five major tasks that constitute data pre-processing. (5 marks)
d) Giving examples, discuss four reasons why data cleaning stage in the KDD process
is necessary . (4 marks)
e) Discuss the causes of noisy data or erroneous data in the database. (5 marks)
f) Differentiate between classification and clustering. (4 marks)
QUESTION 2: 20 MARKS
a) Discuss any five desired features of cluster analysis algorithm. ` (5 marks)
b) Discuss five ways in which the data that has been mined can be visually presented.
(5 marks)
c) A grocery shop sells six items which are Bread, Cheese, Eggs, Juice, Milk and
Yogurt. The shopkeeper also keeps a record of the transactions as follows.
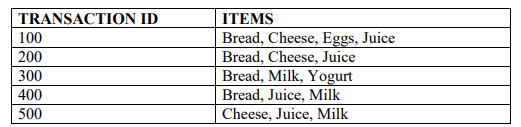
Using the improved naïve algorithm find the association rules with 50% and 75%
confidence. (10 marks)
QUESTION 3: 20 MARKS
a) Define the term data ware house (2 marks)
b) Discuss four benefits of data mining (4 marks)
c) Discuss any four challenges facing data mining. (4 marks)
d) Discuss any five possible discoveries from a data mining exercise. (10 marks)
QUESTION 4: 20 MARKS
a) Discuss five characteristics of OLAP (5 marks)
a) Discuss any four factors that lead to the growth and popularity of data mining.
(4 marks)
b) Describe the various classification of data mining systems (6 marks )
d) Discuss any five factors that you would consider when selection and acquiring a data
mining software. (5 marks)
QUESTION 5:20 MARKS
a) Using two items A and B, define the following terms. (4 marks)
i) Support
ii) Confidence
b) In the context of association rules mining Describe the following terms.
i) Frequent item-sets
ii) Confident rules (4 Marks)
c) In building a decision tree, three possible attributes are considered as split attributes,
the information gain for the attributes A, B, and C are 0.97, 0.029, and 0.15
respectively. Which attribute should be selected for the split and why? (3 marks)
d) With the help of a diagram illustrate the Knowledge Discovery Process. (9 marks)