UNIVERSITY EXAMINATIONS: 2018/2019
EXAMINATION FOR THE DEGREE OF BACHELOR OF SCIENCE IN
INFORMATION TECHNOLOGY/ BACHELOR OF BUSINESS IN
INFORMATION TECHNOLOGY
BBIT 300/BIT 3201A: DATA MINING AND DATA WAREHOUSING
FULL TIME/PART TIME/DISTANCE LEARNING
DATE: AUGUST, 2019 TIME: 2 HOURS
INSTRUCTIONS: Answer Question One & ANY OTHER TWO questions.
QUESTION ONE
a) Explain any two major potential applications of data mining
[4 Marks]
b) Using an example, explain the main difference between nominal and ordered attributes
[4 Marks]
c) With the aid of a suitable diagram, describe the main components of a data mining system.
[10 Marks]
d) Briefly discuss the major difference between Classification and Clustering. List one real
application for each of them respectively.
[4 Marks]
e) There are several data mining techniques used to extract useful knowledge from huge
amount of data. For each technique identified below, describe the technique, identify which
problems it is best suited for, and describe any issues or limitations of the technique.
i) Decision trees
ii) K-Means algorithm
iii) Linear regression
iv) Neural networks
[8 Marks]
QUESTION TWO
a) Using examples, explain the following methods of handling noisy data during the data
cleaning process of data mining.
i) Binning methods
ii) Regression
[4 Marks]
b) In data transformation, the data is transformed or consolidated into forms appropriate for
mining, describe the following data transformation methods:
i) Aggregation
ii) Generalization of the data
[4 Marks]
c) Describe the discretization and concept hierarchy generation technique of data reduction
[2 Marks]
d) Describe classification by backpropagation in neural network
[6 Marks]
e) In the context of Decision Tree induction, explain what is overfitting, and how to avoid it
[4 Marks]
QUESTION THREE
a) Describe data warehouse in context of the following:- Subject-Oriented, Integrated, Time
Variant and Non-Volatile
[4 Marks]
b) Discuss the two approaches of integrating heterogeneous databases
[4 Marks]
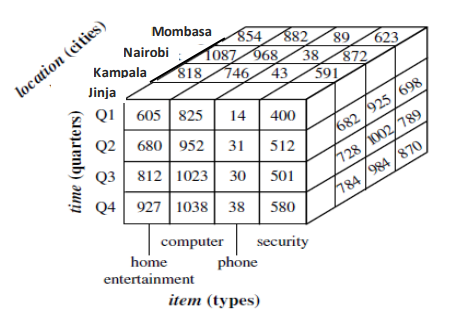
c) Consider the following data cube
Use the above diagram to describe the following OLAP operations
d) Explain the significance of integrating a data warehouse with data mining
[2 Marks]
e) Describe any two schemes that may be used to integrate a data warehouse with data mining
[4 Marks]
QUESTION FOUR
a) Briefly describe the general objective of Association Rules mining.
[2 Marks]
b) Describe the general Apriori Principle.
[2 Marks]
c) Explain the benefits of applying the Apriori Principle in the context of the Apriori Algorithm
for Association Rules mining.
[2 Marks]
d) Describe the frequent pattern mining based on the levels of abstraction involved in the rule
set
[2 Marks]
e) Consider the images ID and their associated tags shown in the table below. Apply
Apriori algorithm to discover strong association rules among image tags. Assume that
min_support =4 0% and min _confidence=70%.
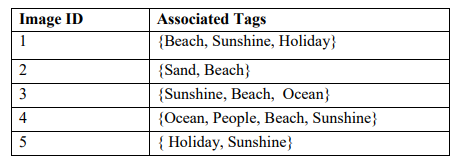
i) Generate candidate itemsets (Ck) and qualified frequent itemsets (Lk) step by
step until the largest frequent itemset is generated. Use table C1 as a template.
Make sure you clearly identify all the frequent itemsets.
[6 Marks]
ii) Generate association rules from the frequent itemsets. Calculate the confidence
of each rule and identify all the strong association rules.
[6 Marks]
QUESTION FIVE
a) Explain the following criteria used for evaluating classification and prediction methods
i). Accuracy:
ii). Interpretability:
[4 Marks]
b) Explain the differences between lazy and eager classifiers
[4 Marks]
c) Briefly explain the main limitation of the Naïve Bayesian Classifier
[2 Marks]
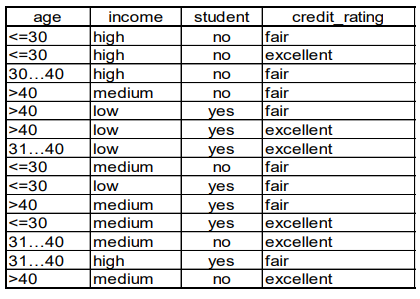
d) A dataset collected in an electronics shop showing details of customers and whether or not
they responded to a special offer to buy a new laptop is shown in table above. This dataset
will be used to predict which customers will respond to future special offers.
Use the Naïve Bayesian Classification to predict whether a customer will buy a computer
given X = (age <= 30 , income = medium, student = yes, credit_rating = fair)
[10 Marks]